Most people interact with AI daily and still have only a vague sense of what's happening under the hood. That's understandable — the tech moves fast, the jargon is dense, and frankly, the outputs feel so coherent that it's easy to just... trust the magic.
But here's the thing: understanding how AI works changes how you use it. And using it well is increasingly the difference between teams that get real value from it, and teams that keep wondering why its results are so hit-or-miss.
So, let's pull back the curtain — no PhD required.
It's not thinking, it's finishing sentences
Before the model can predict anything, your input has to be converted into a form it can work with. That's where tokens come in.
A token is a small chunk of text — not quite a word, not quite a letter, somewhere in between. The sentence you type gets broken apart into these chunks, each one converted into a number. Those numbers are what the model processes. When it responds, it's outputting tokens too — each one generated in sequence, one at a time, before being converted back into the words you read on screen.
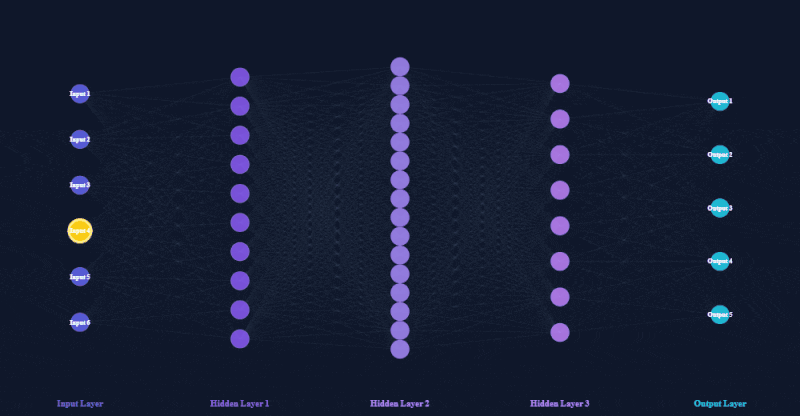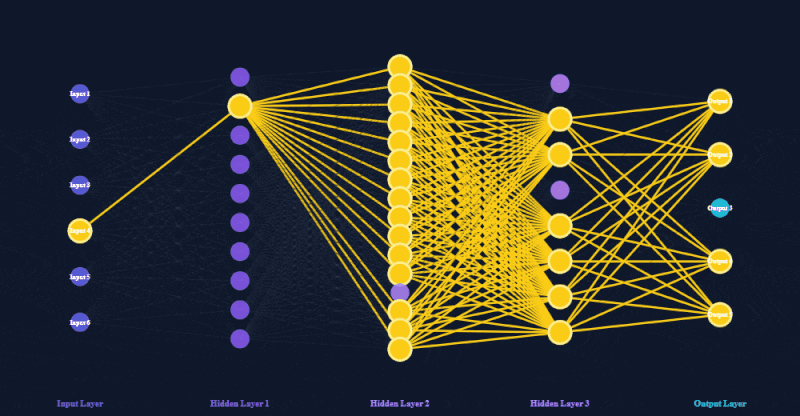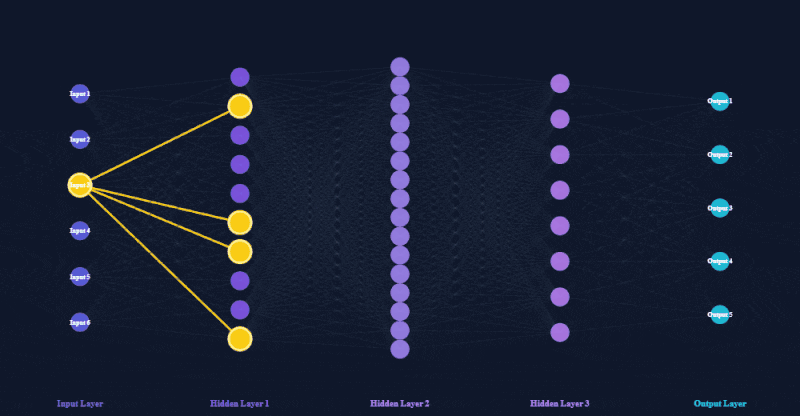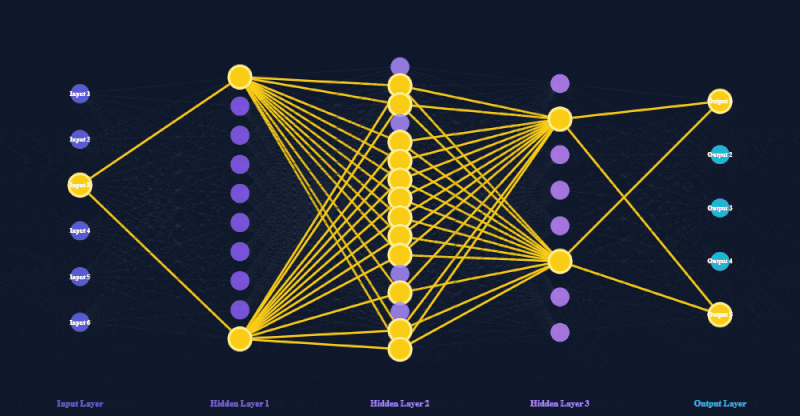
Above: A visual representation of how AI 'thinks' using its artificial neuron network. When a user generates a token in AI, it triggers trillions of calculations that allow the AI to process the user's request, and predict an appropriate answer. This entire pass repeats for each token (and every sentence has multiple tokens) in the AI's response.
At its core, a Large Language Model (LLM) is doing one thing: predicting what word (more precisely, what token) comes next. That's it. It reads your input, converts it into numbers, finds patterns in an incomprehensibly vast mathematical space, and outputs a response — one token at a time.
Every single word it returns requires the model to run through that entire process again. Trillions of calculations, per response, per word. Which is partly why running these things at scale costs a small fortune.
This is fundamentally different from how humans think. We reason, reflect, draw on emotion and lived experience. An LLM does none of that. What it does — what it does extraordinarily well — is pattern matching at a scale that's almost impossible to wrap your head around.
The training that made LLMs this way
Before an LLM can predict anything usefully, it has to learn from a staggering amount of text. DeepSeek V3, for example, trained on 14.8 trillion tokens — roughly equivalent to 123 million medium length novels. (For reference, Google estimated that humanity has written approximately 129 million books total across all of recorded history.) These models are, in a very real sense, trained on nearly everything we've ever written down.
But raw exposure to text only gets you so far. That's the pre-training phase — unsupervised, just the model absorbing patterns. What comes next is where things get more interesting.
Fine-tuning brings in human trainers who run thousands of example conversations, showing the model what a good response looks like. Think of it as hiring a conversational tutor for someone who's read the entire library — the knowledge is there, the tutor teaches it how to use it in conversation. This is also why Claude, ChatGPT, and Gemini all behave differently: different training teams instill different sensibilities, almost like different manners.
After that comes reinforcement learning from human feedback (RLHF) — where raters compare multiple model outputs and indicate which ones are better. Over time, the model's internal weights (the billions of numerical connections that shape its responses) shift toward the preferred behaviours.
And then there's you.
You're already training LLMs (whether you realize it or not)
Every time you rephrase a prompt because the first response missed the mark, every thumbs-down you give, every "that's not what I asked" — that's feedback. And it feeds into how these models evolve.
Here's how that works mechanically: when a response is wrong or unhelpful, the system traces back through the computational path that produced it and makes tiny adjustments to the weights along the way. Nudges, not rewrites. Over millions of iterations, those nudges add up into meaningful behavioural change.
Case in point: we've been working on training a reinforcement-learning model to play euchre (yes, the card game that’s apparently much more popular in our Ontario office than our Manitoba home base — bear with us). The model plays millions of games against itself, gets rewarded for winning, gets penalized for bad moves, and (very) slowly, the neural network reconfigures toward better play.
After 20,000 games, it's still not great.
But the principle is identical to how LLMs are shaped: repetition, reward, adjustment, repeat.
The more people use these models, the better the models get. It’s a feedback loop that isn't incidental — it's foundational.
So what about "reasoning" models?
You may have noticed that some AI models (Claude Opus, for instance), are described as "reasoning" models. So does that mean they’re actually thinking?
Sort of. Not really. But kind of.
Reasoning models break problems into more steps before responding. They generate intermediate thinking tokens — working through the logic before committing to an answer. This is why they tend to perform better on complex problems, math, and multi-step tasks. But they're still doing the same fundamental thing: predicting the next best token, just with more scaffolding around the process.
A useful trick, by the way: asking the model to "think step by step" or to explain its reasoning as it goes improves output quality, even in standard models. You're essentially prompting it to build that scaffolding itself.
What this means for how you use AI
Understanding the mechanism changes the approach.
AI is a prediction engine. Give it good input and it will predict good output. Give it vague, context-free prompts and it will predict whatever seems statistically likely — which may not be what you need.
A few practical implications:
Context is everything. The model can't read your mind. Tell it your role, your goal, your constraints. Don't just ask the question — frame the situation.
Have a conversation, not a transaction. If the response isn't right, say specifically what's wrong and why. "Try again" teaches it nothing. "This is too formal — I need something a client can skim in 30 seconds" gives it something to work with.
Ask it to ask you for clarification. We’ve found vastly better output on the first go-round when we end our prompts with something like, “Before you begin, ask me any questions you need to do this task.” Operationalizing this into your prompt means (in our experience) fewer false starts.
Don't outsource facts. LLMs predict plausible text, not verified truth. They're exceptional at drafting, summarizing, and brainstorming. They're less reliable for precise data, citations, or anything where being wrong matters. You're still the subject matter expert. Use AI accordingly.
The teams getting the most out of AI right now aren't the ones with the most access to it — they're the ones who understand it for what it is: A powerful, endlessly patient prediction engine that gets better the more precisely you direct it.
That's the kind of understanding we build our work around at First Descent Studio. Not hype — just clarity on what these tools can do, and how to make them genuinely useful.
Want a better understand of how you can use AI to improve your workflows and customer interactions? We should talk: contact us to set up a FREE discovery call.